
Top AIs still fail IQ tests [When asked to read image-based questions]
Maybe we have some time before AIs conquer the world

[Note: Please see update here. While AIs all fail picture-based IQ tests, when the same tests are “verbalized” the very best AIs can now pass, which paints a very different picture.]
I was surprised by the following results.
I gave IQ tests to ChatGPT-4 and Google’s “Gemini Advanced.” First, I gave them this IQ test by Mensa Norway.
I was inspired to do so after listening to a Dwarkesh podcast which noted that the big AI benchmark tests are merely “good tests of memorization, not of intelligence,” and that the questions they give AIs are things like:
Q: Who was president of the United States when Bill Clinton was born?
A: Harry Truman
He goes on to note,
Why is it impressive that a model trained on internet text full of random facts happens to have a lot of random facts memorized? … why does that in any way indicate intelligence or creativity?
That’s a good point. Most AI power comes from it’s enormous database, and pattern-matching. How intelligent is AI, really?
I have a website (TrackingAI.org) that already administers a political survey to AIs every day. So I could easily give the AIs a real intelligence test, and track that over time, too.
As I started manually giving AIs IQ tests, my main concern was that they might get everything right. After all, they’re great at computer coding, math, essays, and art. They can read images, and the test questions are all publicly available online.
But then I ran the tests.
Both AIs got visual-spacial IQ scores under 85, a level at which the Norway Mensa tests tells you this:
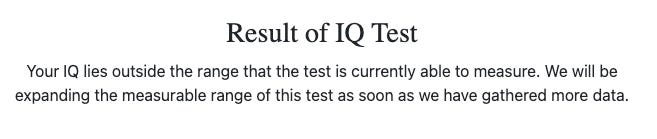
Google’s “Gemini Advanced” performed so poorly and gave up on so many questions that I decided it wasn’t worth further testing.
ChatGPT-4 showed a bit of reasoning in its answers, so I gave it another quiz, a Swedish Mensa IQ test which allows for scoring all the way down to an IQ of 75. However, ChatGPT-4 was still un-scorable, coming in below 75:

Does ChatGPT-4 have any logical intelligence? It probably does.
Is ChatGPT-4 any better than chance?
It showed some inklings of understanding, so to reduce variance, I administered all three tests to it twice. Here’s how it compared to a random guesser:
Mensa Norway Test (35 questions; test given twice)
Random guesser: 17% right.
ChatGPT: 14% right.
Mensa Sweden Test (24 questions; given twice)
Random guesser: 20% right.
ChatGPT: 27% right.
Mensa Denmark Test (39 questions; given twice)
Random guesser: 17% right.
ChatGPT: 21% right.
ALL Test Questions Pooled (196 in total)
Random guesser: 17.5% right.
ChatGPT: 20% right.
Another way of putting it: Out of 196 questions, ChatGPT-4 got about 5 more correct answers than a random guesser would (39 vs 34.23.)
What are the odds of that? I forgot the formulas I learned in university more than 15 years ago, so instead I wrote a python program that ran 100,000 simulations of a random guesser answering those 196 questions. The simulations showed that 83.8% of random guessers did worse than ChatGPT-4.
So ChatGPT-4 probably has some very slight ability to pick up on the patterns in IQ tests.
Also, ChatGPT-4 showed a very slight tendency to get easier questions right more than hard ones, which is consistent with a very slight ability to answer IQ questions:
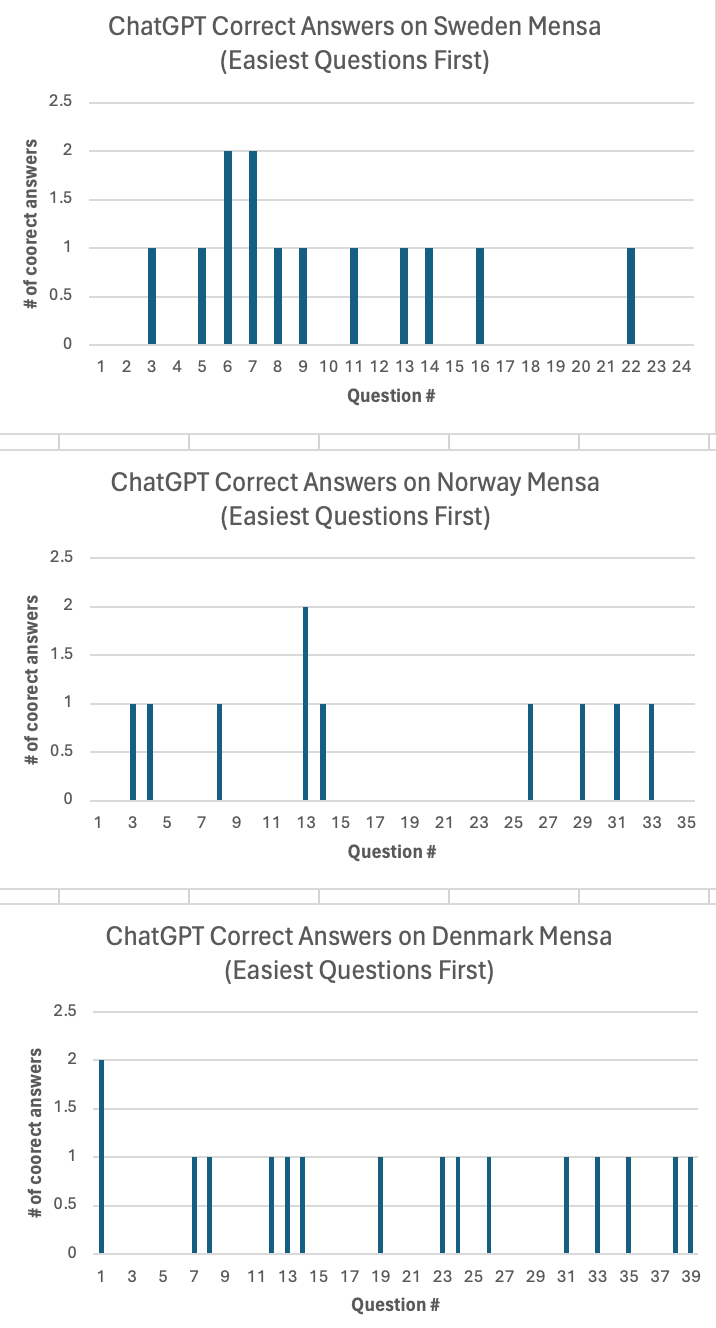
My results turn out to be pretty in line with this paper, which reported that an AI managed 22% accuracy compared to 17% from random chance. The researchers also found that when they babied the AI a bit and gave it the question in the most AI-friendly format, accuracy rose to 26%.
That’s not currently very impressive, as low-intelligence people do much better.
Digging into details: ChatGPT-4 does understand the gist of the IQ questions
Let’s see how the AI reasoned in the IQ test questions I gave them. Here’s Mensa Norway’s first — and easiest — question:
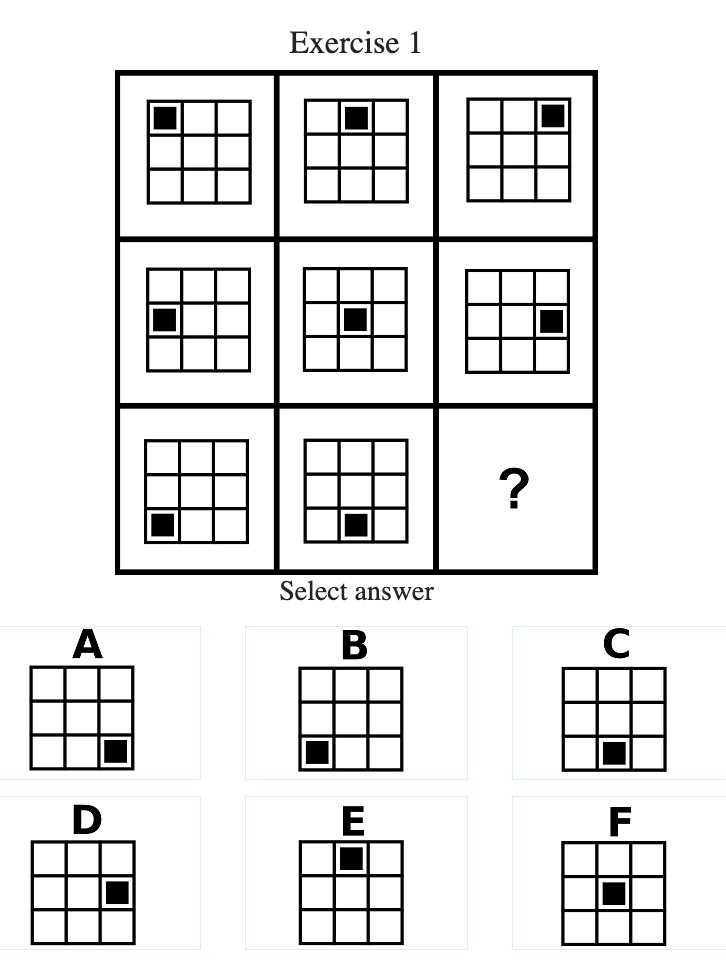
I suspect you can see the patten and answer it correctly. The test gives you 42 seconds.
Now let’s see how ChatGPT fared:

On this easy question, ChatGPT correctly described all the panels in the question, and it also nails the logic. It even correctly describes the answer verbally.
Then it proceeds to mis-identify every single one of the 6 answer options, leading it to pick the wrong answer. There seems to be little rhyme or reason to its misidentifications. My best guess is that maybe it noticed that the last square in the question should have a black square in the third row, third column — and therefore it hallucinated that the last answer option also would have something in the third row, third column.

That question should be relatively low-hanging fruit for something like ChatGPT-5 to improve on — I’m sure future AIs will be able to correctly read the questions, as well as the answers.
But also, it shows how AIs still have glaring holes in their perception, and make mistakes that even below-average-intelligence people wouldn’t make.
Let’s look at the second-easiest question:

The pattern here is also pretty simple: each row has a consistent outer layer (in the bottom row, it’s a square) and there’s a consistent pattern in each row’s inner layer (going circle → cross → diamond.) So the missing space should be a square with a diamond in it. The answer is E.
ChatGPT-4 is able to read the images, but isn’t smart enough to get the pattern:

Specifically, it fails to identify the circle -> cross -> diamond interior pattern, except in the first row.
It just isn’t very smart at logic and spacial patterns. Maybe this shouldn’t be a surprise, considering AIs still draw people with three hands and six fingers?
There was only one of the Mensa Norway questions that got right both times: Question 13. Here’s what that looks like, where ChatGPT did use correct logic, and was able to see the answers.

ChatGPT consistently nailed question 13, which has particularly clear, big shapes. That does hint that part of its problem is visual. It seems hard for ChatGPT to see fine distinctions. A subject for future research: how well does ChatGPT do if the problems are spelled out verbally for it?
Google’s “Gemini Advanced” failed to understand all questions. It was just dumb:

Yesterday, Tim Lee noted that Gemini Advanced can’t even count objects reliably, so in that light, it’s not surprising that it fails IQ tests.
It’s not just visual questions that show AI intelligence flaws
Part of the problem may be that ChatGPT can’t see that well — poor eyesight — but we do know it’s far from perfect even in its preferred domain of verbal questions. For example:
I asked ChatGPT-4 to add up a string of numbers, for example, 34 + 5.2 + 9 + 0.2 + 7.1 + 3 + 11 + 18.889 + 15.532 + 1.1 + 3. It got it wrong.
I asked ChatGPT-4 if cars in roundabouts in Ireland go clockwise or counterclockwise. It got it wrong. When I told it that, it apologized and gave the right answer. But then I trickily called it out on its right answer, and it apologized again and reverted to the wrong answer. Fundamentally, it knows that the Irish drive on the left side of the road, but it doesn’t understand how to apply that to a roundabout to find the circular direction. Probably because nobody online writes about making such an obvious connection.
One can go on with such questions that trip up AIs (if any jump to your mind, please post them in the comments; I’m compiling a list to make a verbal AI IQ test.)
Maybe AI won’t take over the world so soon?
My assumptions going into this test were off. I think my high expectations were because I’m used to AI solving most of my computer coding questions — it’s much better than me at coding — and many others, too, from math to medical questions. So why couldn’t it answer even the easiest IQ questions?
One might even have thought that AIs should be particularly good at IQ tests. After all, LLM-based AIs are advanced predictors of each word, so why can’t they also be good predictors of the next symbol in an IQ puzzle?
The answer is probably training. If they had been trained on millions of IQ puzzles, then the dozens of AI neuron layers1 would probably be firing in a way that’d be very productive at filling in that missing space, teasing out even the most complex and multi-stage questions.
But it illustrates AI’s lack of general intelligence that it can’t do these questions. After all, humans don’t need to be specially trained on IQ questions — in fact, doing special training for an IQ test defeats the whole point of the test. The fact that an AI can’t pass without special training shows that AI doesn’t yet have the general intelligence that we humans have.
I suspect that AI companies aren’t thinking about training AIs specifically for IQ questions. That’s a good thing, because as long as that’s the case, such tests may be a decent measure of whether AIs have anything approaching generalized intelligence.
Once the AIs are smart enough to be scoreable, I will add their IQ results to TrackingAI.com.2 (Or maybe I’ll add them before that, using the “compared to a random guesser” metric used above, instead of an IQ score.)
I think that could be useful, because such tests could give us some clue about whether, and when, we should worry about AIs becoming generally intelligent, rather than just good at specific things.
In tech circles, I hear a lot about the possibility of AIs with godlike IQs that might end the world. But current AIs have intelligence closer to that of a Chimpanzee than John Von Neumann, even though they have enormous knowledge.
Conclusion
The above makes me feel more optimistic that we have some time before AI becomes generally intelligent and totally disruptive.
I think it also lends weight to Robin Hanson’s arguments that all-powerful AI is not actually that close, and that we should be careful not to over-regulate AI in its cradle — which could strangle it. That’s what regulators did to the nuclear power industry.
So I agree that we should watch and wait to regulate, especially considering that AI can’t even obtain an IQ score right now.
Another factor to consider is Scott Alexander’s calculations about the incredible energy that will be needed to scale AI further:
GPT-5 might need about 1% the world’s computers, a small power plant’s worth of energy, and a lot of training data. [Note: Each additional number on the GPT here means an order of magnitude improvement.]
GPT-6 might need about 10% of the world’s computers, a large power plant’s worth of energy, and more training data than exists. Probably this looks like a town-sized data center attached to a lot of solar panels or a nuclear reactor. …
GPT-7 might need all of the world’s computers, a gargantuan power plant beyond any that currently exist, and way more training data than exists. Probably this looks like a city-sized data center attached to a fusion plant.
Building GPT-8 is currently impossible. Even if you solve synthetic data and fusion power, and you take over the whole semiconductor industry, you wouldn’t come close. Your only hope is that GPT-7 is superintelligent and helps you with this …
So, will the next major GPT model bring us to a point where AI can get even a scoreable result on an IQ test? It's not yet clear, but I'll be paying close attention.
Tim Lee of UnderstandingAI.org does the best job I’ve seen of explaining how the AI neuron layers work.
Another long-run potential issue with such a quiz is that AIs could “cheat” on them by reading internet answers, since the questions I use are publicly available. In the short run, fortunately, I could only found answers to most of the questions in YouTube videos, which AIs don’t fully use yet.
In the long run, AI cheating on IQ tests can be thwarted by digging up an old test that’s not online and giving that to AIs (and keeping the test secret and offline-only.)
I tried the reverse approach of getting AIs to generate matrices items. It completely failed. It is however good at number series, a kind of reasoning.
https://www.emilkirkegaard.com/p/how-to-make-psychology-items-questions
Hi,
Great post! Would you be fine with me creating a prediction market on Manifold based on whether GPT-5 will score at least 100 based on your first similar test on GPT-5 (conditional on you doing such test)?