


Massive breakthrough in AI intelligence: OpenAI passes IQ 120
OpenAI's new "o1" model may have an IQ as high as 120

Worried about AI taking over the world?
You probably should be.
That’s my new takeaway after testing OpenAI’s new model, “o1”1 this morning. It blows all other AIs out of the water on the Norway Mensa IQ test:

I had become blasé about AI progress after my initial tests in February, because there was approximately zero IQ improvement since then.
This week, that all changed.
Specifically, o1 got 25 out of 35 IQ questions correct, far above what most humans get. You can see its answers to every question here, and below some specific examples:
Examples of o1’s answers to IQ questions
Here’s the hardest question on the quiz, which it gets right:
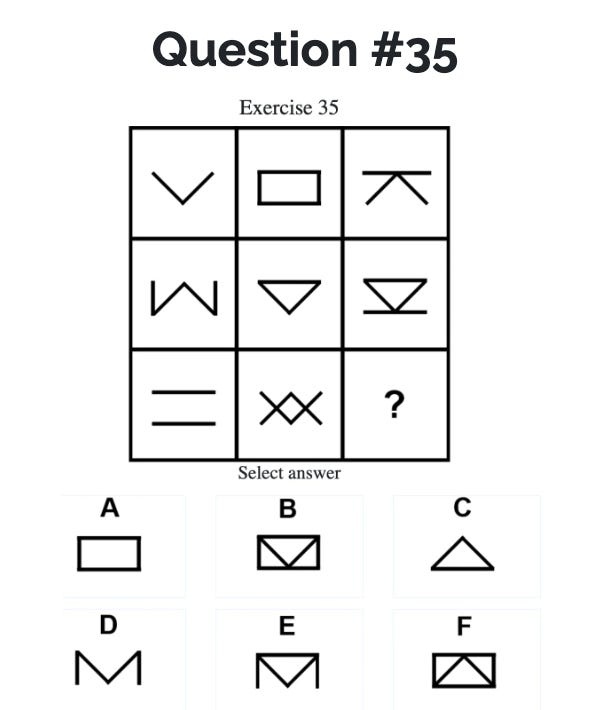
The correct answer is probably not obvious to you. It’s certainly not obvious to me.
o1 gives this rationale:
Option D — By analyzing the patterns in the grid, we see that each column combines certain components to include all elements (V, upside-down V, rectangle sides) by the third row. In the third column, components Rleft and Rright (the rectangle's sides) have not yet appeared. Therefore, the correct answer for the empty cell is Option D, which includes the normal 'v' and the two sides of the rectangle, completing the set of components for that column.
So it says it picked “D” because it noticed a pattern in which each column should contain all possible elements. In order for the 3rd column to contain all elements, it needs the sides to be in the bottom row, which are in “D”.
It neglects to explain why it picked “D” over “B” and “F”, but a YouTube explainer I found says that’s the correct choice because "each of the 8 pictures is described only by the repetition in the diagonals ... B and E contain extra lines, so D is the correct answer."
The YouTube explainer also gives a different logic (focusing on diagonal patterns) than the pattern o1 picked up on, and I almost wrote here that o1’s description was wrong. But it seems to me like the simpler pattern it detected is also valid.
Now let’s go to a question that’s more at my level:

OpenAI o1 correctly answers and explains:
In the third row, the pattern involves combining the lines from the first and second cells and removing any common lines. The first cell has lines to 4:30, 6:00, 7:30, 9:00, and 10:30. The second cell has lines to 1:30, 3:00, 6:00, 7:30, and 10:30. The common lines are at 6:00, 7:30, and 10:30. Combining the unique lines from both cells (1:30, 3:00, 4:30, 9:00) gives us Option F.
That’s exactly right!
o1 also gets some questions wrong. The following question involves the exact same pattern as Q24 above:

But this time, o1 only manages to see the additive part of the pattern, and it misses the “remove common lines” part. So it gets it wrong:
In the grid, the pattern suggests that combining the features of the first two cells in each row results in the third cell. In the third row, combining the incomplete square with vertical and horizontal lines (third row, first column) and the complete square (third row, second column) gives a complete square with both vertical and horizontal lines crossing the midpoint. This matches **Option E**.
It’s not infallible, yet! See this footnote if you want to see the correct answer.2
The IQ improvement is NOT because the questions are in the training data
The most common concern with the above kind of analysis is that maybe some AIs have a “cheat sheet”; maybe they’ve been trained on these very questions.3
To deal with that possibility, in April, a commenter on this blog, Jurij, who is a Mensa member, offered to create new IQ questions for me. I then created a survey consisting of his new questions, along with some Norway Mensa questions, and asked readers of this blog to take it. About 40 of you did.
I then deleted the survey. That way, the questions have never been posted to the public internet accessed by search engines, etc, and they should be safe from AI training data.
Using blog readers’ survey responses, I was able to align the difficulty of the new offline-only IQ quiz, and the Mensa Norway one, so that “100” should mean the same on both tests.
Then I gave the new, offline-only test to AIs. The AIs do significantly worse on this from-scratch offline-only test:

But, importantly, the magnitude of o1’s lead is roughly the same [edit: still huge]! That suggests that o1 represents a massive real improvement in AI reasoning ability, not merely the inclusion of IQ-specific training data.
Further research could help with precision of scores
Since AI vision is not yet good enough,4 it’s possible that one reason the AIs do relatively poorly on this new test is because the verbal descriptions of the questions are not written as well as they could be, and further research could include multiple wordings of the questions, written by different people, to get a sense of how sensitive the AIs are to how the questions are described.
I would also like to do further research to establish where the human average really is on these quizzes, because, when readers of this blog took the Mensa Norway questions, they averaged just 103. While I suppose it’s theoretically possible that readers of this blog who voluntarily take an IQ test are just super curious people, but not too much better at pattern analysis than average, it’s a lot lower than I’d have expected.
I asked the creator of Norway Mensa, Olav Hoel Dørum, how his test was normed, and he said it was based on giving his questions to 80 humans who had official IQ scores.
While these norming methods should get us somewhere, it would be worth norming these tests on larger populations centered around average human intelligence. That would give us a more precise comparison between humans and AIs.
For now, I think it’s a good estimate that the leading AI IQ probably now lies somewhere between 100 and 120.
o1 passes a quick sanity check using “common sense” questions
In my first (outdated) post on AI intelligence, I wrote about two cases where ChatGPT-4 failed me:

I re-asked these questions of o1. It got them both right. I also tried to trick it by telling it that it was wrong, and suggesting instead the wrong answer that ChatGPT-4 had once given. It resisted my pushing and reaffirmed its correct answers.
Conclusion — the future is upon us
The new o1 model shows that fast projections about AI progress are on track.
In my initial major AI IQ analysis, I extrapolated from Claude’s improvement trend to see where AI IQ might soon end up:
… look at the consistent progression:
Claude-1 was hardly better than random. It got 6 answers right, giving it ~64 IQ.
Claude-2 scored 6 additional points per test (worth ~18 IQ points).
Claude-3 scored yet another 6.5 points, worth ~19 more IQ points, bring it up to above the human average.
… now consider the release dates …
Claude-1 March 2023
Claude-2 July 2023 (4 months production time)
Claude-3 March 2024 (8 months production time)
A very simple extrapolation suggests that we should therefore expect to get Claude-4 in 12 - 16 months, and that it should get about 25 questions right per test, for an IQ score of 120. [OpenAI’s o1, now 6 months later, got exactly 25 out of 35 questions right]
After that, in another 16 - 32 months, Claude-5 should get about 31 questions right, for roughly 140 IQ points.
After that, in another 20 - 64 months after that, Claude-6 should get all the questions right, and be smarter than just about everyone. That’s 4 - 10 years out in total, adding up all the time periods.
Of course, that progress is not a given. Anthropic could run up against budget constraints, energy constraints, regulatory constraints, etc.
I now think that timeline is holding up, and that OpenAI has always been about 6 months ahead of Anthropic/Claude, behind the scenes.
If so, then we should start seeing AIs breaking 140 IQ in 2026.
That’s soon! Hold onto your hats.
For the record, I was quite surprised by these test results, after having been lulled into a false sense of complacency after there was no AI progress beyond IQ 100 for the 6 months since I started tracking this.
I also think all this makes clear that AIs are intelligent, and are reasoning. They do have access to all of the world’s knowledge, but they’re also more than that.
Contrary to one strand of conventional wisdom, AIs aren’t merely regurgitating words pulled out of an algorithm. Yes, they are fundamentally doing that — but predicting the next word gets so complex that logic and reasoning seem to arise out of the process of prediction. Is that maybe also the same process from which human higher-order intelligence originated from? Unclear, but there’s no doubt that seeing the dawn of AI intelligence is starting to give us some hypotheses about our own.
I’m also newly optimistic again about AI-related stocks and chip-makers, even after their recent run-ups in price. AI is also energy intensive, and so perhaps those companies could do well, too.
If you find research like this useful, and you have extra disposable income, consider subscribing below to support it! It cost me $1,000 just to get automated (API) access to o1, for example, so any offset in operational costs is appreciated:
You can also help just by subscribing for free, hitting “like” on this post, and sharing it!
P.S., if you’re skeptical about how smart OpenAI’s o1 is, I encourage you to try it for yourself. Paying users of ChatGPT can find it here, as o1-preview:

Why is it called “o1”? OpenAI-o1-preview tells me: “You're noticing the term "o1 preview" because it's a code name or version identifier for the model you're interacting with. OpenAI uses internal code names like "o1" to distinguish between different models or versions during development and testing phases. The "preview" part indicates that this version is a pre-release or test version made available to users before the official launch.”
B
There are some reasons to think it’s not the case that the AIs have the questions in their training data — for example, the AIs are more likely to get harder questions wrong. AIs also sometimes give different reasoning than human guides give, as shown regarding question 35.
There are also some reasons to think it is the case. For example, OpenAI is known to have scraped YouTube videos, and some videos on there do have the answers (but then again, OpenAI scraped under 1% of all YouTube content.)
AI vision models aren’t get good enough to read the IQ questions consistently, although the top vision model, Gemini Advanced, now scores IQ 70 — better than random. So AI vision plus reasoning is on its way.
I don’t know that we should be celebrating this.
I didn't know about this test. I gave it a try a had 133 which is more than gpt :)