


AI IQ scores (mostly) confirmed, using new offline IQ test
Major AIs suffer 8% loss on novel questions; all AIs have 20% loss

How smart are AIs? Knowing that can help us answer questions like “will AIs take our jobs?” and “will AIs kill us all soon?”
AIs seem smart partly because they have lots of knowledge. They’re trained on far more information than any human has seen. But their intelligence — their ability to use logic and reason to analyze questions — often reveals basic errors.
In my last deep dive, I gave a verbalized matrix-style IQ test to AIs, and found the following:
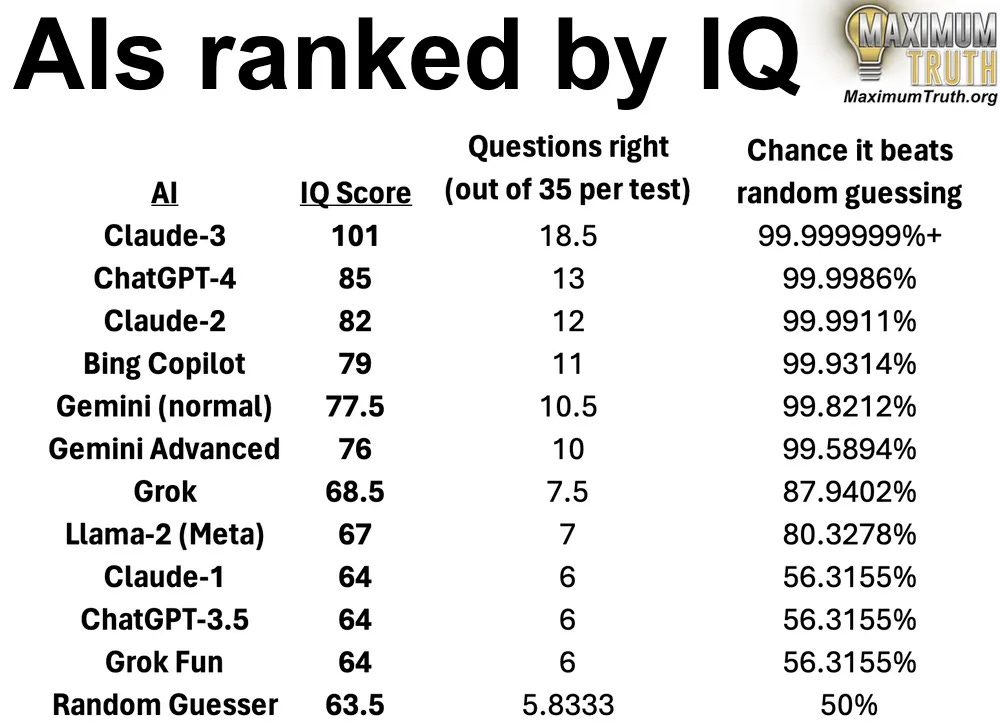
The results seem plausible to me. Interacting with AI chatbots feels like dealing with someone who’s not that bright, but who knows how to write, and has access to an Encyclopedia of Everything.
However, several smart people raised a plausible concern: perhaps the IQ questions and answers (which came from Mensa Norway’s online quiz) were already in the AI training data. AI reporter Timothy B Lee wrote:

Another commenter wrote:

The concern makes sense. AI companies have sucked in massive sections of the web for AI training. A recent Verge headline notes, “OpenAI transcribed over a million hours of YouTube videos to train GPT-4.” That’s particularly relevant, because YouTube does contain videos with the test answers and reasoning. That said, there are approximately 156 million hours of YouTube videos, so ChatGPT has logged less than 1% of all YouTube content.
In order for humans to get a fully valid IQ test result, they need to have not practiced or thought in detail about IQ questions. Did the AI do that? Did it “cheat”?
Did the AIs “cheat” by using IQ questions in their databases? Preliminary evidence
Some patterns suggest that AIs do not memorize the answers.
That’s because AIs are much more likely to get easy questions right, compared to hard ones.
The below graph shows the results of two test administrations for the smartest AI. The tall bars mean it got the question right both times it was asked, the short bars mean it got it right just once (and no bar means it got the question wrong both times):
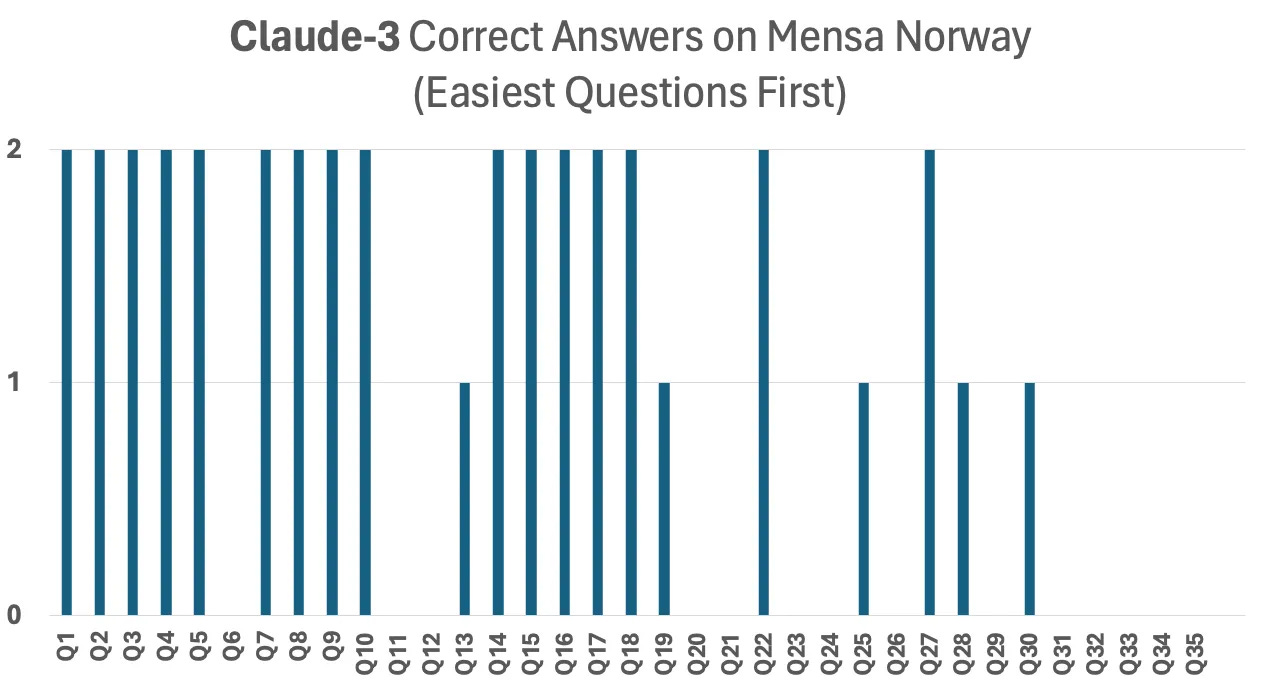
That pattern doesn’t look like the answers of someone with an answer key. Instead, it suggests that the AI was working through the problems using pattern matching skills, in the same way a human might.
The reasoning that AIs provide as they solve their questions also backs that up. In some cases, the AI takes upon itself to draw the IQ problem in question it was read:
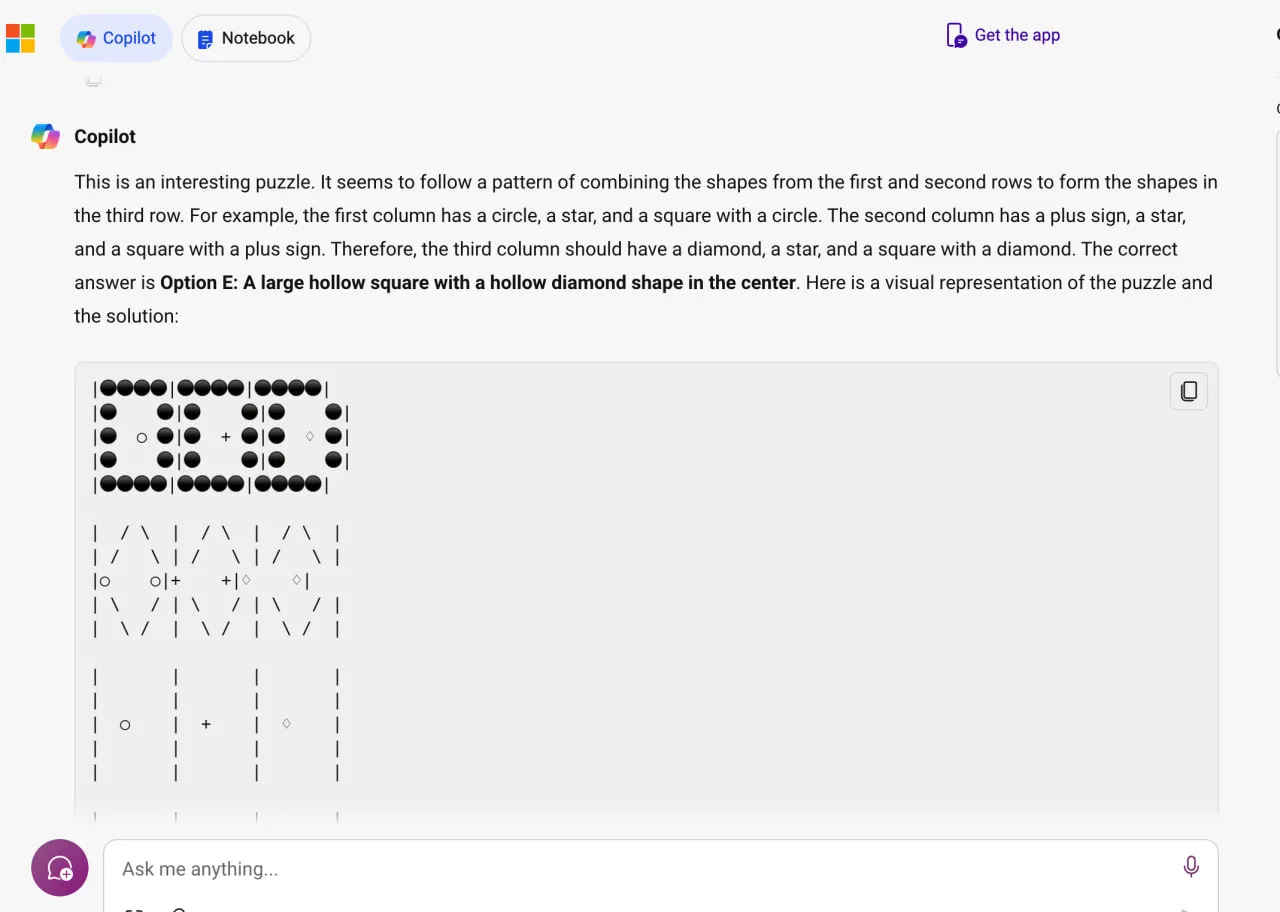
Drawing out the problem is something that no online answer key would suggest; humans can see the questions, and have no need to re-draw them.
Despite the above, it remains possible that AIs do have the IQ questions Q&As in their database, but just use them imperfectly.
Additionally, even if the AIs don’t “cheat” yet by having the questions in their database — in the future, they certainly might, as they are trained on larger and larger datasets.
So it would be really nice to have an offline test which will always be able to answer the question of whether AIs are passing IQ tests due to intelligence, or due to having the answers in their database.
Creating a new offline-only test to run on AIs
Jurij, a Mensa member and commenter here who creates IQ questions as a hobby, offered to create new IQ test questions. I took him up on that.
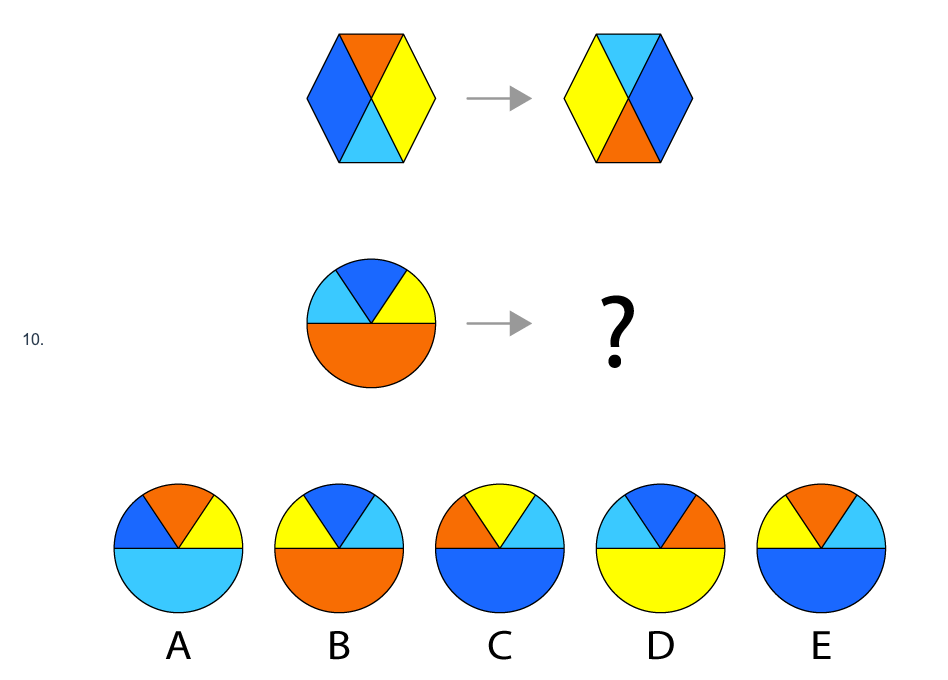
Jurij created 16 questions from scratch, which were quite different in appearance from the Mensa Norway ones, while still testing the same kind of abstract pattern logic. Here is an example of one of his easier questions (which is not part of the AI test; I can’t publish those online, or it would invalidate future tests with it):
Once I had Jurij’s questions and answers together, I still needed to “norm” them — in other words, to figure out how hard the new questions were compared to the Mensa Norway questions that I previously gave AIs.
To do that, I paired the 16 new questions with all the even-numbered questions from Mensa Norway’s online IQ test, and I then asked blog readers to take the quiz.
59 readers took it (thank you very much! I hope it wasn’t too painful.)
35 of the responses were usable, meaning the test-taker got to the end, and hadn’t seen the Mensa Norway questions before. Out of those, here’s how the scores broke down — quite a wide range:

That breakdown is based just on the 17 Mensa Norway questions that respondents answered.
I suspect the scores are too low. However, the formula I used is faithful to the Mensa Norway scoring — I sanity-checked it by manually entering in 16 correct answer into their test, which gives you a score of 95. My test used half of their questions, and also gives you, for example, 95 for 8 answers correct.
So I suspect that their test isn’t perfectly calibrated, and 100 actually represents a somewhat above-average person.
That will require more research to nail down (specifically, a survey of the general population.)
But in the meantime, it’s not particularly relevant for determining whether the AIs “cheat” — the important thing is that this is fundamentally the same scoring formulas1 by which AIs were graded in the last analysis.
The quiz is now offline, and precautions were taken to prevent the new questions from being exposed to the public internet while they were briefly online for blog readers to take.2
So, how do the new questions compare to the old ones in difficulty?
Methods: “Normalizing” the new test questions
The purpose of my survey was to determine the difficulty of the new, offline-only questions, compared to the Mensa Norway questions.
The survey results revealed that two questions were ill-formed (fewer people got them right than one would expect by chance, and also, the top-scorers were also not better at them.) Those two questions were dropped.
Another question turned out to have two correct answers; that question was kept, and either correct answer was given credit.
That left 14 new questions, which had good predictive power of people’s Mensa Norway scores.
Out of the 14 new questions, respondents averaged 8.94 correct. Out of the 17 Norway Mensa questions, they averaged 9.2 correct.
Since there were fewer new questions, that means each one was slightly easier; survey takers got 63.8% of new questions right, compared to 54.1% of Norway Mensa questions.
Since each new question was slightly easier, after adjusting for randomness and the size of the tests, the scoring formula counts each correct answer as worth 88% of a Mensa Norway answer. Formulas are detailed in footnote 1.
This method ensures that the average IQ of each set of questions is the same (both are 103.) But each individual has a different score using the new questions, and the distribution is slightly different:

Ability at answering the new IQ questions, and the Mensa Norway ones, correlates with R^2 at .45. That means that differences in IQ estimates based on Norway Mensa predict close to half of the differences in the IQ estimates based on the new questions:

That’s far from a perfect correlation, but I think it’s enough to get some sense of how the AIs are at an offline-only IQ test.
Now that we’ve figured out how hard the new questions are compared to the old ones, and the relevant formulas, we can go on to scoring the AIs based on the new test.
Result: Top AIs did 8% worse with novel questions
Here are the new results, alongside the old ones:

Looking at the top 5 AIs that I had previously scored (Claude-3, ChatGPT-4, Bing Copilot, Gemini, and Gemini Advanced), they had a loss of 3 IQ points. Those AIs would have averaged 6.6 correct answers, if they’d be equally good at the different questions; instead, they got 6.1 correct answers. That’s an 8% reduction in performance.
Note that we’re talking about 3 fewer IQ points, on a test that has been normed to how humans did on the two kinds of questions. In other words, the tests have already been set to have the same average score when humans take them — but the AIs do not get quite as high of a score on the novel, offline questions.
Result: AIs overall did 20% worse with novel questions
The AIs overall averaged about 6 fewer IQ points using the new test which has never been online.
The 6 IQ-point difference translates to roughly 1 fewer question correct out of the 14 asked. The average AI would’ve gotten 5 questions right, instead of 4, if it had done as well as it does on the Mensa Norway questions. So that’s a 20% loss in performance.
This suggests that there might have been a bit of “cheating” in terms of the AIs using IQ questions that were online to craft their answers.
But it doesn’t necessarily show “cheating.” Here are other possibilities:
— It could be random chance (though that seems unlikely; every single except ChatGPT-4 did worse on the new test.)
— It’s possible that my translations were inadvertently be worse, or harder, this time.
— It’s possible that the questions themselves are harder for AIs. In particular, the new questions involve more unique shapes, and have more extraneous detail, than do the Norway Mensa questions. For example, the order of shapes is sometimes random, and the shapes are often things like a “stylized Z” rather than just a triangle. These extraneous details are likely to be more easily overlooked by humans using “common sense”, but when I do the verbal translations, I have to describe this extraneous detail to the AIs, and it has to realize that the real pattern lies elsewhere. IF it were the case that AIs really are just as good at novel offline-only questions, I suspect this would explain it.
Meta’s Llama-3 is a new AI, and an outlier
For some reason, Meta’s Llama-3 (which did not exist when I did my previous analysis) does decently on Norway Mensa questions, but is no better than random at the novel, offline questions. That’s surprising, and suggests that perhaps Llama-3 has the questions in its training data more than any other major AI.
It makes sense that AIs saw relatively little dropoff in performance
Timothy B Lee of Understanding AI, in his comment quoted above, cited a study that found that AIs solved 50-80% fewer math problems when given novel questions that don’t exist online.
I found nothing like that kind of dropoff with IQ questions. I think that makes sense, because it’s very rare for people to study for IQ tests. The answers were not that easy for me to find online (though I eventually found them in a YouTube video.) In contrast, math problems have been a core part of the educational system forever, and they live just about everywhere on the internet.
Conclusion: AI IQs are fairly robust, especially among top AIs
Overall, the ranking of AIs based on the new questions is pretty similar to the ranking based on the Mensa Norway questions. Here it is again:

Using the new questions, I also still find a massive performance difference between the “ChatGPT-3.5” generation AIs, and the “ChatGPT-4” generation AIs.
This suggests that the test is picking up something real. After doing this analysis, I’m still just as excited to use this method once the “ChatGPT-5”s start rolling out. I think that’ll give us some sense of whether AIs actually threaten jobs on a mass scale soon, and also whether it’s scaling in a way that’s on track to become omnipotent — or not.
The reason it’s an interesting test is because it differentiates AI knowledge from AI intelligence, in a way that other tests like GMATS and SATs don’t.
I’m now working on adding this novel AI IQ test (and the old one, too) to TrackingAI.org, where both tests will run weekly, providing an IQ range for each AI.
Weekly runs will both help with any problems caused by small sample sizes, and also detect trends over time!
Formula for Full Norway Mensa:
63.5 + 3 * (correct answers - 5.833) [5.833 is the number of questions one would get by chance.]
Formula for Mensa Norway short version (even-numbered questions only):
1) Take # of correct answers on 17 even-numbered questions
2) Subtract (17/6), for the number of questions one would get by chance.
3) Multiply by (35/17), to account for the fact that we don’t have the full question set.
4) Call that resulting number “adjusted correct answers”, then do: 63.5 + adjusted correct answers * 3
In full, this can expressed as: 63.5 + 3 * ((correct answers - (17/6))*(35/17))
Formula for Offline Answers:
1) Take # of correct answers on the 14 valid questions (so, not including 9 and 11.)
2) Subtract 3 (aka (1/5)*13 + (2/5)), for the number of questions one would get by chance. Note: 2/5 is because one question has two valid answers. The “/5” as opposed to “/6” is because the offline test questions have 5 possible answers, not 6.
3) Multiply by (35/14), to account for the fact that we don’t have the full question set.
4) Multiply by 0.8823, to account for the fact that the new questions were slightly easier than than the Norway Mensa ones.
5) Call that resulting number “adjusted correct answers”, then do: 63.5 + adjusted correct answers * 3
In full, this can expressed as: 63.5 + 3 * 0.8823 * ((correct answers - 3)*(35/14))
The Mensa Norway questions were in black, and the “offline” ones were in color.
Also, here are the precautions taken to ensure the test stayed offline: While the quiz was take-able, the images were hosted on a server of mine with a “norobots.txt” file to deter scraping, and the site was never located by a search engine. The images were on it for only a few days, before being deleted, along with the quiz.
Side note: there was an error in the formula for the scores shown to the 35 people who took the test, which caused, for example, one person to be shown a score of 168 after taking the test. It should have be in the 140s. Aside from that, scores shown to takers were generally accurate within 10 points. The correctly-calculated score breakdown is in the bar chart in this post, and was exclusively used in this analysis.
You make me curious to see the offline questions. Though I understand the problem I wonder if there might be a way to cut out scrapers without impacting humans. I have some ideas based on fronting the questions with a service like cloudflare which allows you to redirect based on the requester's source (and indeed to make the bot click on the "I'm not a robot" box, which it ought to fail at). This would let humans see your test questions and exclude the various web crawlers including the AI ones.
It should be possible to test this by putting some other information behind a test block and see if that information shows up in AI programs or indeed in google/bing etc.
Maxim, great work. Where do you see this heading in the near future? Are we going to have AIs that exceed human intelligence in the coming five years?